
Aman Sharma
Upcoming MS CS @ Georgia Tech · Creator of EsoLang-Bench
I'm an upcoming MS CS student at Georgia Tech (Fall 2026) and a researcher at Lossfunk AI Lab. I work on building AI systems that adapt to new domains - spanning continual learning, persistent memory for LLM systems on OOD domains, test-time adaptation, and sample-efficient training and inference. I'm particularly interested in how multi-agentic systems can maintain and update knowledge through memory harnesses that enable robust generalization beyond their training distribution.
I also collaborate with the MIT Media Lab (with Ayush Chopra) on large population models and multi-agent coordination - most recently on the Ripple Effect Protocol, a decentralized alignment framework developed with MIT and Cisco. My research interests lie in continual learning, multi-agentic systems, reinforcement learning, and efficient LLM systems.
Previously, I was a Google Summer of Code fellow at NumFOCUS (implementing automatic differentiation rules for image processing in Julia), an ML engineer at Ikigai Labs (benchmarking LLMs vs traditional ML), and an MLH Fellow building high-performance Rust systems for Solana. I won 12+ hackathons and conducted ML workshops and teaching sessions for 200+ undergraduate students.
Research Highlights
Multi-Agent Systems
- Ripple Effect Protocol - decentralized coordination framework for LLM agent populations (MIT & Cisco)
- Do LLMs Deceive? - Emergent deception and strategic behavior in multi-agent auctions
LLM Reasoning & Efficient Systems
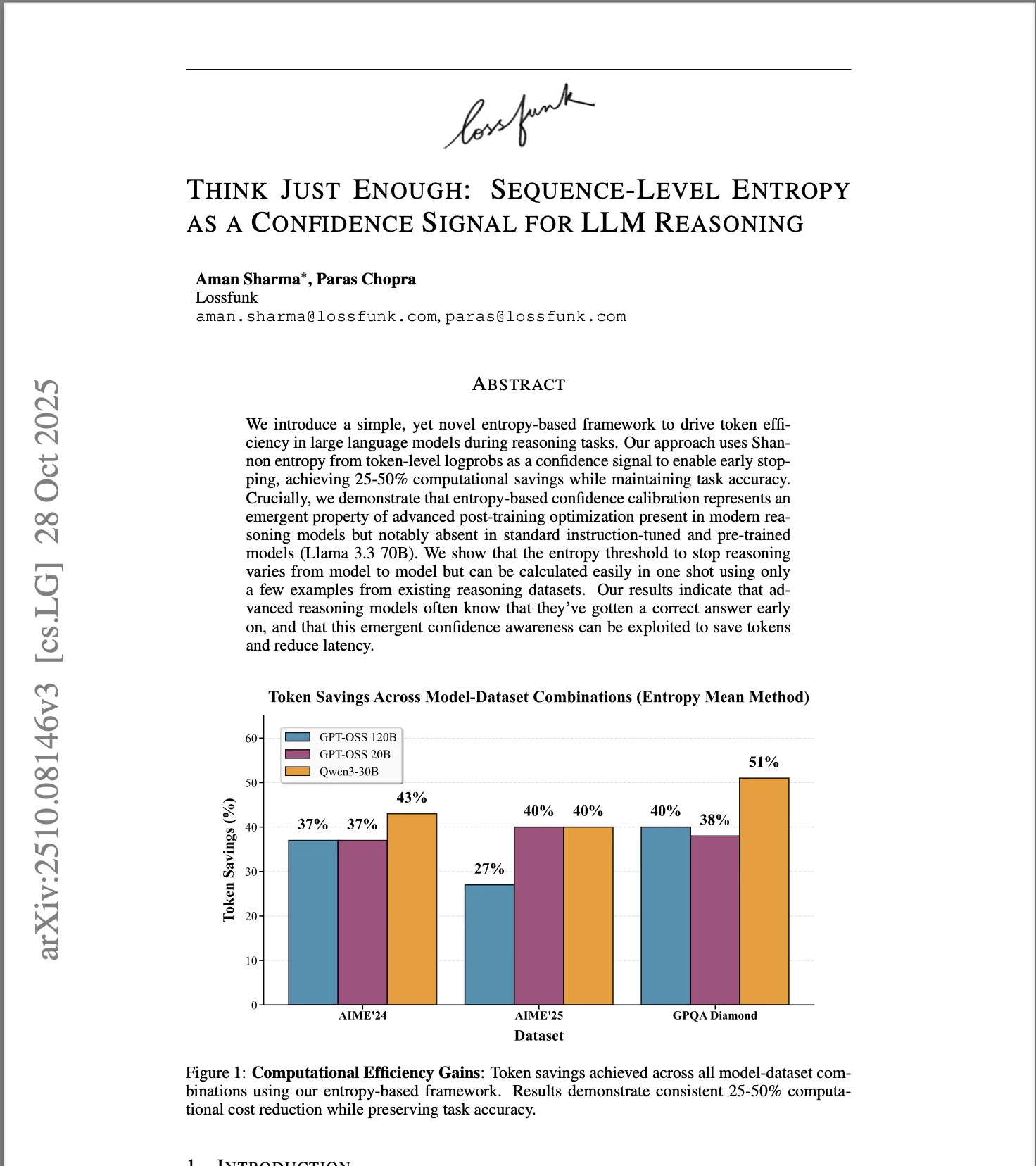
- Entropy-based confidence signals for adaptive reasoning depth - 25-50% token reduction
- Inverse-entropy voting - sequential scaling beats parallel self-consistency at matched compute
LLM Evaluation
- EsoLang-Bench - evaluating genuine reasoning via esoteric programming languages; frontier models drop from 85-95% to <12% in zero-shot/few-shot settings
My World of Thoughts
-
Frontier models make real discoveries in math and code and almost none in robotics, biology, or open-ended science. The dividing line is not difficulty, it is how cheap, exact, and automatic the ground truth is in each domain. Where a verifier exists, reinforcement learning scales inside LLMs and discoveries follow; where it does not, the same models stall. The conceptual opener to my inverse RL series, on recovering the reward from demonstrations for the physical world.
-
The bedrock of inverse reinforcement learning: recovering the reward and cost function behind an expert's behaviour from their demonstrations alone. A step-by-step walk through Abbeel-Ng (2004) and MMP (2006) on a 12x12 gridworld, with interactive widgets and full derivations.
-
Four frontier multimodal models (Gemini 3.1 Pro, Claude Sonnet 4.6, GPT-5.4, Qwen 3.6 Plus) appraised fifteen paintings worth $1.46 billion in two conditions: image only, and image plus a four-word metadata label. Visual recognition of fine art is largely solved at the frontier; what separates the models is what they do with that recognition.
-
We present EsoLang-Bench: frontier models score 85-95% on standard benchmarks but <12% when evaluated on esoteric programming languages with no training data.
-
Sequential reasoning wins in 95.6% of configurations at matched compute, with accuracy gains up to 46.7%. Introducing inverse-entropy weighted voting.
-
Using sequence-level entropy as a confidence signal to reduce inference tokens by 25-50% without sacrificing accuracy.
My World of Research




News
| Apr 2026 | Admitted to Georgia Tech MS CS (Fall 2026) |
| Apr 2026 | EsoLang-Bench published at ICLR 2026 Workshops ICBINB & LLM Reasoning |
| Apr 2026 | LLM Deception in Auctions published at ICLR 2026 Workshop MALGAI |
| Dec 2025 | Two papers accepted at NeurIPS 2025 Workshops (FoRLM, Efficient Reasoning) |
| Oct 2025 | Ripple Effect Protocol published, part of Project Iceberg |
| Jun 2025 | Joined Lossfunk AI Lab as Researcher |
| Feb 2024 | Started research collaboration with MIT Media Lab |
| May 2023 | Joined Ikigai Labs as ML Engineer |
| Jul 2022 | MLH Fellowship - Hubble Protocol (Solana/Rust) |
| May 2022 | Google Summer of Code - NumFOCUS (Julia) |
Get in Touch
Interested in collaborating, have research questions, or just want to chat? Drop me a message.