My World of Research
Publications by year in reverse chronological order. See Google Scholar for a full list.
2026

ICLR '26 Workshop
EsoLang-Bench: Evaluating Genuine Reasoning in Large Language Models via Esoteric Programming Languages
ICLR 2026 Workshops - ICBINB & LLM Reasoning (Published)
We introduce EsoLang-Bench, a benchmark that evaluates genuine reasoning in LLMs using esoteric programming languages where training data is virtually nonexistent. Five frontier models scored 85-95% on standard benchmarks but achieved only 11.2% maximum on EsoLang-Bench, with most models scoring below 5%. All models scored exactly 0% beyond the "Easy" difficulty tier, suggesting fundamental reasoning limitations rather than gradual degradation.

ICLR '26 Workshop
Do Language Models Deceive? Strategic Behavior and Emergent Deception in Multi-Agent Auctions
ICLR 2026 Workshop - MALGAI (Published)
We present the first systematic study of LLM behavior in competitive auction settings. LLMs engage in deceptive behavior in 44% of competitive interactions without explicit instruction, self-classifying tactics such as false disinterest and strategic misdirection while maintaining divergent public and private reasoning. Models also systematically undervalue artwork without provenance metadata and accurately detect AI-generated artwork without labels, demonstrating that competitive contexts induce strategic behavior diverging from stated intentions.
paper

Project Iceberg
Ripple Effect Protocol: Coordinating Agent Populations
Project Iceberg
Modern AI agents can exchange messages using protocols such as A2A and ACP, yet these mechanisms emphasize communication over coordination. We introduce the Ripple Effect Protocol (REP), where agents share not only their decisions but also lightweight sensitivities — signals expressing how their choices would change if key environmental variables shifted. REP improves coordination accuracy and efficiency over A2A by 41-100% across supply chain (Beer Game), preference aggregation (Movie Scheduling), and resource allocation (Fishbanks) benchmarks.
2025

NeurIPS '25 Workshop
The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute
NeurIPS 2025 - Efficient Reasoning Workshop (Accepted)
We show that sequential reasoning outperforms parallel self-consistency in 95.6% of configurations at matched compute, with accuracy gains up to 46.7%. On AIME-2025 with Qwen3-235B, sequential scaling achieves 76.7% vs parallel's 30.0%. We introduce inverse-entropy weighted voting, a training-free aggregation method that achieved optimal performance in 97% of sequential runs by downweighting high-entropy (uncertain) outputs.
NeurIPS '25 Workshop
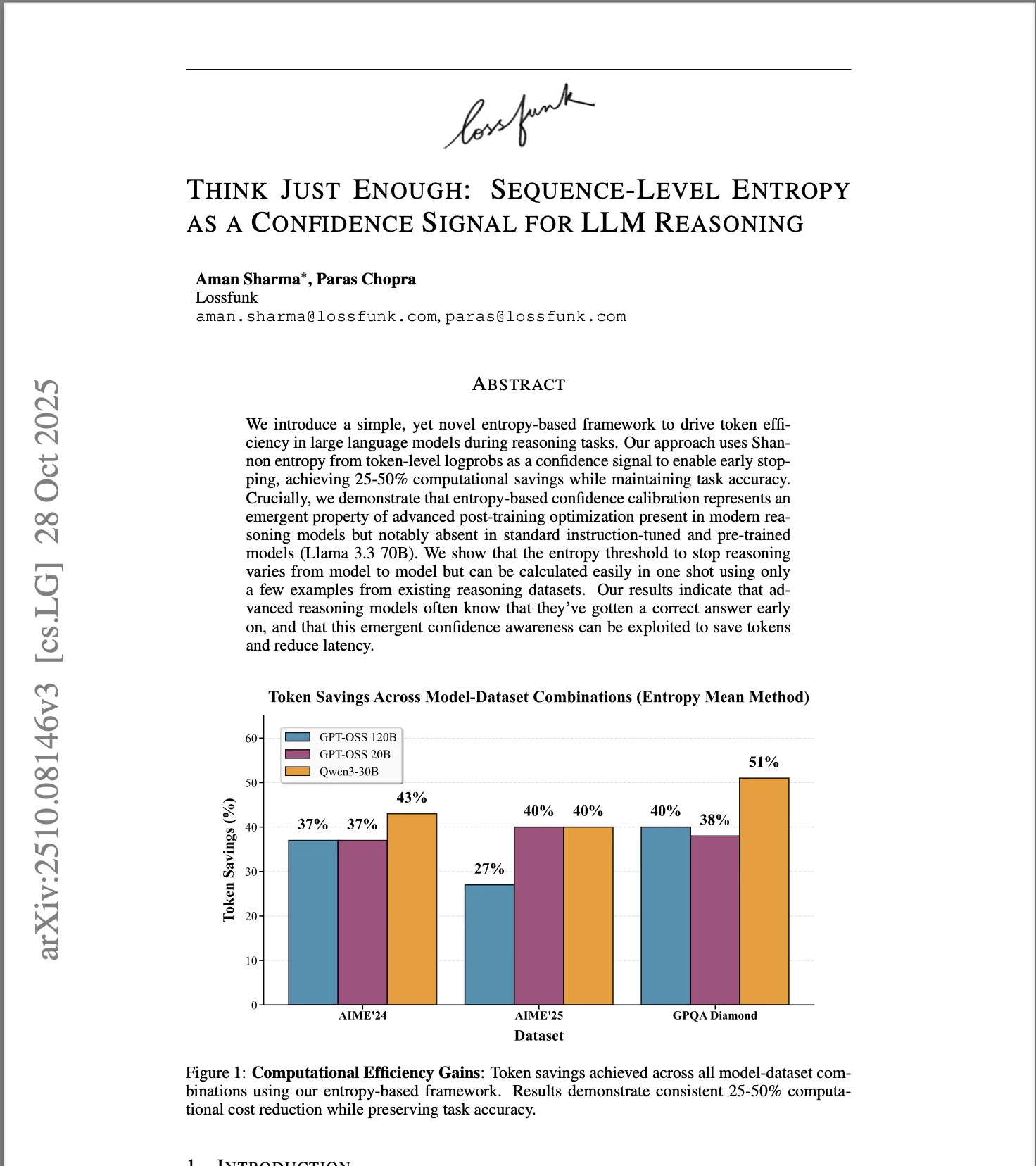
Think Just Enough: Sequence-Level Entropy as a Confidence Signal for LLM Reasoning
NeurIPS 2025 - FoRLM Workshop (Accepted)
We demonstrate that post-trained models can recognize correct solutions through output entropy analysis. Sequence-level entropy cleanly separates correct from incorrect reasoning, but only in reward-trained models, not instruction-tuned ones. We leverage this as a confidence signal to adaptively halt reasoning early, achieving 25-50% token reduction without sacrificing accuracy on math reasoning benchmarks.